Gaal: strace for agents

best insights are properly aged ones
strace for agents
Our dopamine circuits seem to be quite delta driven. First times running agents and loops feel like a pure wow. Sparks of joy hit after every wave of subagents gets back with yet another milestone completed and yet another open source repo published through the 2026 Cambrian explosion of agentic tooling.
Some time later - it turns out to be just a new routine. Just the way things work now. Codex wrapped in a telegram bot is on mute - because it’s porting Python lib to Rust and it’s 100 notifications over the last hour. It will probably do alright - it’s well prompted - guidelines are in place - and the process has been well scoped in advance - so it’s mostly operational noise at the moment - no need to babysit agents anymore. They have grown up and soon to leave the builders nurture nests…
I mean, even jumping from the sky for a second time is not as bright as the first one. Our 20W biological supercomputer is wired in a way that pushes us to try new things by lowering highs for each N+1 repeat.
Though some things solidify and sharpen through the “normalisation” of agentic pipelines. A thousand and one skills you have downloaded from j-stack, e-stack, p-stack, … - typically become the burden your agents carry from API call to API call - ballooning your bill. Tools for the sake of tools become rather corporate-ish fossils - taking 10 times more time and tokens in order to get shit done.
It’s okay. Models evolve. Harnesses implement the most popular community tools; agentic patterns slightly change - and the ladders, bolts and suspensors are becoming of less relevance - since the facade of the future is starting to look more or less sane
What remains
Those who remain - are typically of two categories. Something with non-zero marginal utility - or something of rather sentimental value. I hope that the main hero of this story will rather be of the first category. Though not without elements of the second one - I mean - it’s called after Isaac Asimov book hero - Gaal Dornik.
Coffee talks with friends about agentic flows became quite mundane these days. You are unlikely to surprise anyone with Claude analyzing all of the reels you have ever liked, or all of the Spotify songs you have ever listened to. It’s a bold new reality where everything is much more possible given the drive and inspiration.
Though there is a thing that has recently surprised me.
I thought that everyone has their own tracing and telemetry - some concept of strace, but for agents.
By strace I do not mean “memory” in a cute AI assistant sense. More like forensics - what happened, which prompt or agent caused it, which files and tools were touched, and where to open the actual session when you need the substance.
It turns out that agentic sessions traceability, observability and continuity are still major bottlenecks from time to time. Don’t get me wrong though - there are things like “agents with perfect memory” - based on RAG, Obsidian CLI or some other fancy tech. But they do have their own pros and cons. Quite often they do not age well - rather becoming digital bureaucracy layer after yet another major labs update.
Materialized in code, the concept of strace on the other hand - has survived for almost 5 months - at least for me! Which seems to be an eternity these days - I hope it doesn’t die of old age as I am writing about how I’ve ended up building it.
Those who remember
I’ve always had an itch about data structuring. I guess - early AI-age bias. Itch became especially noticeable with the LLMs taking off - Imagine having alien-like restless intelligence that can process literally anything - so it’s only a matter of formatting to turn real-world problem into a carefully crafted context for them!
Context engineering spree started back in 2025 for me - with the failed startup of mine - serving Ethereum blockchain data in a form of deterministic markdown - with distributions, deviations and skewness / kurtosis being served on a plate with a gold rim. The market died before I managed to GTM.
The itch remained. Opus 4.5 has been the beast that seemingly denied the need for any kind of data normalization - its agentic capabilities allowed for “zero-shot” in-domain learning.
But the idea of data normalization rather went one step upwards in the space of meta concepts. I’ve spent around 2-3B tokens through my agentic endeavours of 2025 (input tokens I mean, input and cached). It’s my typical week now - in the post-harness era of agents - 3-5B input tokens with ease. And all of those tokens, sessions, tool calls are logged somewhere on the drive! They could be parsed, analyzed and USED for something useful (in theory).
One of the use cases could be a strace-like tool! This is approximately the logic of how deterministic markdown rendering received a proper rebirth somewhere mid-February 2026 - in a tool called Gaal
What problem are we solving
The vanilla dream of mine has been to “never lose an insight or detail” through some carefully orchestrated tooling. Undead spirit of “deterministic markdown concept” gave this idea, frankly speaking - bones and a body - though not alone - a proper database has been born in the process of tool creation as well.
Problem set (approximate):
- I want all of my agentic sessions to be properly indexed - turns classified and stored in database - so that every tiny bit of agentic madness on my machines could be traced down to my prompt / “you are absolutely right” or genuinely bright idea.
- I want to be able to track down every concept / prompt / agent explanation / cool workaround through thousands of my sessions
- I want to be able to “debug” tools and prompts by inspecting the agents’ decision making - so that prompts and tools could be improved. It’s especially useful for subagents and agents launched by code for somewhat deterministic pipelines
- I want to have summaries / handoffs for key sessions with agents
- Codex inside Claude and Claude and Gemini inside Codex were a lot of fun - until you try to trace who did what - I needed the unified logs and traces layer
(bonus point) I want to have cool “day checkout” feature - where all of my activity through day / week / month is automatically fetched / analyzed - delivered as a nice text file with tables!
So the problem was not really memory. It was traceability, debuggability and continuity - can I find the session, understand the decision, and hand off useful state without carrying the whole machine in my head?
it’s basically classical naive dream of interactions with AI that do compound
Core Ideas
I shall probably explain the general intuition here - for other details code will speak for itself. The core idea of “deterministic markdown view” - is to transform any other data format into token-efficient view that will give an agent all of the necessary context. Reading raw JSONL logs of Claude or Codex sessions is totally feasible - but token overhead there is insane.
Rendering something like:
---
conversation_id: 0xhexspeak
.....
---
Hooman:
Implement just X
Agent:
you are right to pushback, I am doing A, B and C
*tools being called, some reasonable truncation*
*tool results, some reasonable truncation as well*
A is done!
....
....
....can turn 500k tokens plus JSON monster into something like 10-20k tokens max - which allows an agent reading it to actually understand the context of a whole session.
Second core idea is to add a database layer for the things that should be discovered fast: sessions, prompts, file reads and writes, commands, errors, handoffs, tags - the boring but useful facts. In current Gaal it is literally SQLite plus a Tantivy/BM25 full-text index over normalized facts. Such a database layer could allow for quality-of-life commands like
gaal who wrote slop.md,gaal who read slopslopslop.mdgaal who ran slop-backdoored-tool
which give session ids where that has happened. These commands are not trying to explain the whole universe. They route an agent to the right session ids. Then inspect and transcript give the richer context of WHAT has happened and WHY this has happened.
Database acts mostly as the discovery and routing layer; markdown views are where the substance lives.
And this all is wrapped into the agent-first UI as per the best SF guidelines. Properly ax-tested as well. The core idea behind ax-testing and polishing CLI tool for agents is that error codes your tool gives are the best learning opportunity for an agent.
Moreover - a fun power play is to use Gaal agent traces in order to actually see how they are using tools - how many turns they need before the correct call - what are common failure modes; and this is all as simple as gpt 5.5 xhigh auditor reading 5k tokens of deterministically rendered markdown.
Another power play is to have some flexible handoff logic. This is the opt-in memory layer, not the base index: create-handoff compresses 10-20k of tokens into a domain-specific summary of ~0.5k-1k tokens - and then recall can fish those generated handoffs out later by project / keywords / headline-ish substance. LLM-generated - the prompt can be fine-tuned for any objective and angle you need.
And finally - generating on-demand deterministic markdown views - for a slice of time for example - proved to be quite a good feature as well. activity is not live monitoring; it uses the index to find candidate sessions and then goes back to source traces to render the slice.
For other stuff - better check the code and the tool itself.
Gaal started as a traceability tool. But after using it for months, I think the more important thing is the pattern underneath it: raw logs are almost never the right interface for agents. The useful interface is a layered set of views.
Even bigger idea
Cambrian explosion of open source tools had quite specific “dresscode” - Rust. I mean - proper Rust TUI - probably with ratatui. It’s been not much of an exception for me - apart from not using TUI - I’ve decided to build something agent-first - CLI + skill. CLI that human hands will never type commands for.
Building agent-first tooling for some time I’ve arrived at quite interesting insight about somewhat optimal architecture of context serving for agents. This idea has crystallized during optimizing video analytics pipeline for a friend of mine.
Long story short - we want to build a context hierarchy. Assume that we have 50M plus tokens of data. And we need to have some sort of agentic utilities above them. 2 years ago it would probably have converged to some sort of a vector database, reranking, BM25 and yada yada yada.
My current read is converging toward a much more elegant solution (prove me wrong - I am judging by conferences and speakers from Estados Unidos IT giants): layered faithful views over the data.
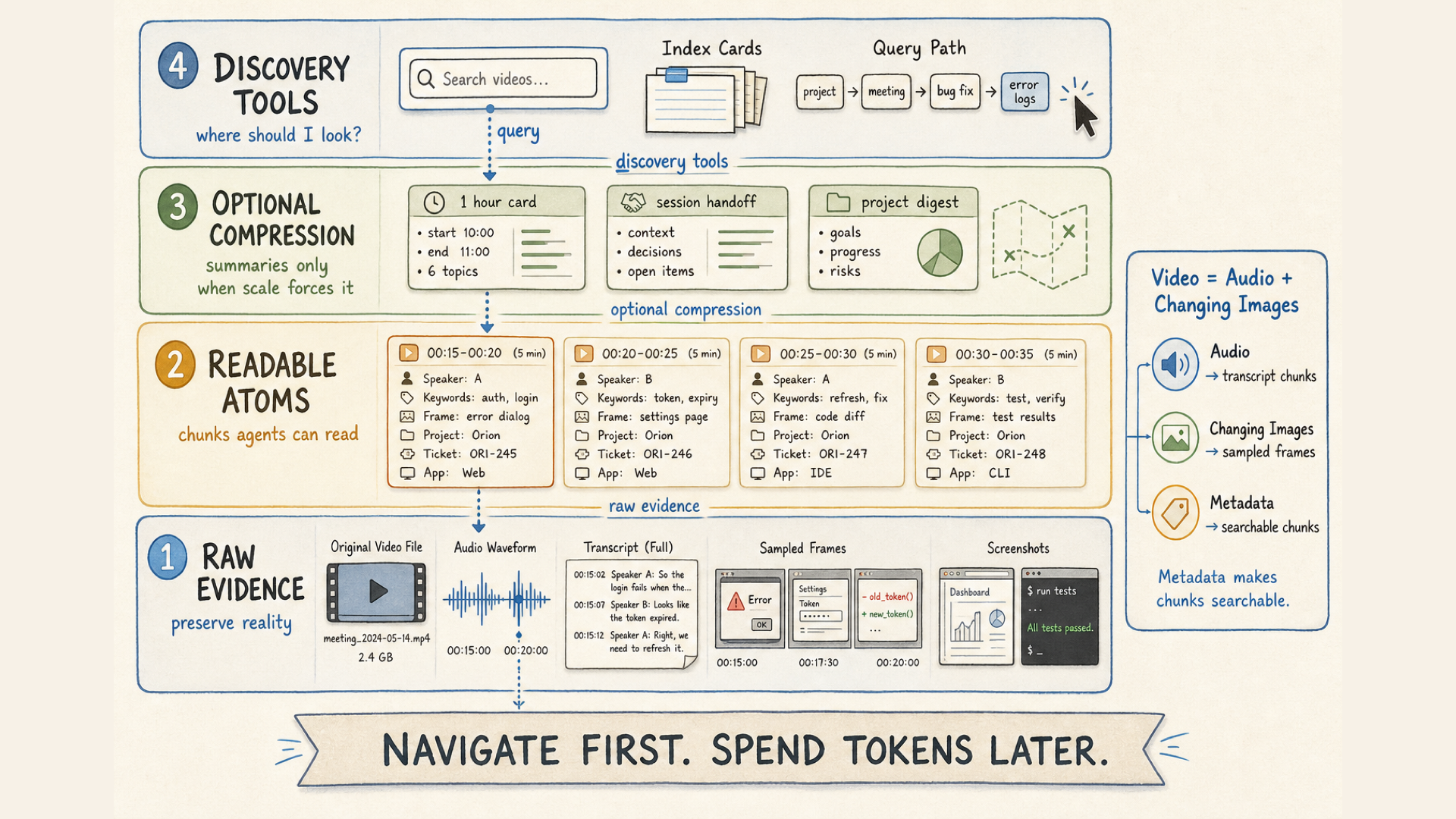
Gaal does this for agent traces: raw logs at the bottom, indexed facts for discovery, markdown views for substance, handoffs for continuity. Same shape can be applied to video, screen recordings, research corpora, support tickets - whatever giant blob you want agents to navigate without going bankrupt.
The pattern is not “summarize everything”. That loses too much. The pattern is: keep raw data intact, make smaller faithful views over it, then build tools that let an agent move from search result to compact view to raw evidence only when needed.
Let me elaborate more about it for video processing:
Video = Audio + Changing Images
RAW EVIDENCE Preserve reality. Do the expensive extraction once.
For video this starts with the boring but sacred stuff: original file, audio transcript, speaker turns if they matter, sampled frames, and cheap visual descriptions of those frames. Audio becomes text. Changing images become annotated frames. Chunking can be something like 5 minutes, but this depends on the domain and objective.
This layer is not supposed to be elegant. It is supposed to be recoverable. You process it once, preserve it, and reference it only when higher layers become suspicious or the task requires precision.
READABLE ATOMS Turn raw evidence into chunks an agent can actually read.
This is where raw evidence becomes useful working context. For each audio chunk, extract metadata: keywords, speaker IDs, projects mentioned, ticket IDs, decisions, maybe emotional tone if it matters for the domain. For each frame chunk, generate a 100-1000 token description of what happened visually, plus domain-specific metadata: applications open on screen, UI states, product names, diagrams, error messages, machines, objects, whatever the agent may need later.
These are the core atoms your agents will reference. They should preserve enough substance that an agent can reason from them without immediately opening raw video. This is the analogue of deterministic markdown views in Gaal.
The most important nuance here is to create well-crafted data & metadata structure.
OPTIONAL COMPRESSION Use summaries only when scale forces it.
Depending on the amount of data and the objective, you may jump straight from readable atoms to discovery tools. But if you have enormous amounts of data - thousands of video hours, millions of log lines, 200M-token sessions - even atoms become too much.
Then it might be worth generating compact views over groups of atoms: one-hour video cards, session summaries, project digests, handoff-style notes. For audio chunks this might mean “what was discussed in this hour?” For visual chunks it might mean “what was happening on screen across this segment?” Same source, smaller view.
But this layer is optional and lossy. It is a map, not the territory. Use it to navigate, not to replace the evidence.
DISCOVERY TOOLS Help the agent find where to look before asking what happened there.
This is the crown jewel of the concept: agentic tooling for discovery and drill-down. Search by speaker ID. Search for chunks where Jira tickets were visible on screen. Search for places where project X was discussed. Search by app name, object, keyword, timestamp, error message, customer, machine, repo, whatever your domain needs.
I treat this as the “minimal Turing complete set of tools” for the corpus: enough commands for an agent to locate and fetch anything that matters. The agent should be able to move from broad query -> compact view -> readable atom -> raw evidence. Not “load everything into context”. Navigate first. Spend tokens later.
Core idea here is to build a token-efficient way to discover necessary batches of data with high precision first - and then serve high-quality views to agents so that they can excel in any domain.
Instead of conclusion
This ended up being quite long-in-the-production post - took me almost 2 weeks from the start to these very words. Funny enough - I just wanted to write about Gaal - the tool I use daily but never properly told about - but then I’ve realized that there could be a bigger picture around this idea. The bigger picture that has led me to this tool creation. The bigger picture that is quite coherent with the beliefs I have about agentic systems for the last year or so - about optimizing the way agents consume context - discover and consume.
So I’ve put this idea out here in the wild - in order to see how well it will age.
P.S. I use tokscale for token accounting and as an additional layer for day checkouts - it allows to track how many tokens have been used where and when, with which model. Gaal doesn’t have a first-class token accounting yet - but I will probably add it later on.